1. Tujuan
[Kembali]- Memprediksi apakah seseorang terkena penyakit diabetes berdasarkan beberapa parameter lain pendukung
Indonesia merupakan negara peringkat kelima penderita diabetes terbanyak di dunia. Hal ini dipengaruhi pola hidup yang tidak sehat kemudian ditambah dengan kurangnya kesadaran masyarakat untuk mengecek apakah dia terkena diabetes atau tidak. Algoritma KNN (K-Nearest Neighbor) dapat digunakan untuk memprediksi apakah seseorang mengidap diabetes.. Dari hasil data set yang dilatih kemudian diekspor untuk dapat digunakan bahasa pemrograman phyton. Pada aplikasi phyton yang dikembangkan user diminta untuk menginputkan data pregnancies (angka kehamilan seseorang selama dia hidup), kadar insulin, kadar glukosa, BMI, Tekanan darah, riwayat diabetes dalam keluarga, ketebalan kulit, dan umur dalam bentuk slider. Data input diroses dengan algoritma KNN untuk menentukan hasil Outcome berupa angka hasil positif diabetes atau negatif berdasarkan kedekatan data baru yang di input dengan data lain yang telah dilatih.
- Diabetes
Diabetes adalah penyakit kronis yang terjadi ketika pankreas tidak lagi mampu membuat insulin atau ketika tubuh tidak dapat menggunakan insulin yang dihasilkannya dengan baik. Insulin adalah hormon yang dibuat oleh pankreas, yang bertindak seperti kunci untuk membiarkan glukosa dari makanan yang kita makan melewati aliran darah ke dalam sel-sel dalam tubuh untuk menghasilkan energi. Semua makanan karbohidrat dipecah menjadi glukosa dalam darah. Insulin membantu glukosa masuk ke dalam sel.
Indonesia merupakan salah satu dari 10 besar negara dengan jumlah penderita penyakit diabetes terbanyak di dunia. Pada tahun 1995 Indonesia yang masih tergolong negara yang baru berkembang dan menempati peringkat ke-7 dengan jumlah penderita diabetes sebanyak 4,5 juta jiwa. Peringkat tersebut diprediksi akan naik menjadi peringkat ke-5 pada tahun 2025 dengan perkiraan jumlah penderita 12,4 juta jiwa. Pada tahun 2021, International Diabetes Federation (IDF) mencatat bahwa Indonesia telah berada di posisi kelima dengan jumlah pengidap diabetes 19,47 juta dengan jumlah penduduk 179,72 juta. Ini berarti prevalensi diabetes di Indonesia sebesar 10,6%[1].

Masyarakat umum pada kenyataannya tidak menyadari bahwa dirinya menderita penyakit diabetes sehingga terlambat untuk melakukan diagnosa sejak dini. Sehingga penderita dikhawatirkan tidak menjaga pola hidupnya dan tidak merawat diri karena tidak menyadari sebelumnya. Selain itu pola hidup yang tidak sehat juga dapat menyebabkan terjangkit diabetes di usia muda. Akibatnya ketika mereka datang ke layananan kesehatan sudah dalam kondisi yang parah. Oleh karena itu dibutuhkan sistem yang dapat mendeteksi apakah seseorang telah terjangkit diabetes atau tidak[2].
K-Nearest Neighbor (KNN) merupakan salah satu algoritma dengan teknik lazy learning yang menggunakan metode klasifikasi terhadap objek berdasarkan data yang jaraknya paling dekat dengan objek tersebut. KNN juga termasuk dalam kelompok instance-based learning[3].
Pada algoritma KNN, data berdimensi q, jarak dari data tersebut ke data yang lain dapat dihitung. nilai dari jarak inilah yang digunakan sebagai nilai kedekatan antara data uji dengan data latih[4]. Terdapat berbagai macam metode yang dapat diterapkan pada algoritma KNN dalam menghitung jarak kedekatan objek dengan data terdekat, namun yang paling umum digunakan adalah metode Euclidean Distance, bahkan digunakan sebagai default pada library SKLearn pada bahasa pemrograman Python saat menggunakan algoritma KNN. Metode penghitungan jarak lainnya yang umum digunakan pada algoritma KNN yaitu Minkowski Distance dan Manhattan Distance[5].
Dataset yang digunakan adalah Pima Indians Diabetes Database yang dipublikasikan oleh UCI Machine Learning pada situs kaggle. Alasan kami memilih dataset tersebut karena telah dipakai dan di vote count hampir 3 ribu pengguna pada situs kaggle yang merupakan sebuah portal komunitas ilmu data dan pembelajaran mesin di seluruh dunia.
Untuk dapat mendeteksi apakah seseorang menderita diabetes atau tidak maka dibuatlah sebuah sistem pendeteksi diabetes dengan menggunakan algoritma klasifikasi k-nearest neighbor (KNN).
- Konsep Dasar

python
dibuat pertama kali oleh Guido van Rossum di tahun 1991. Saat ini ada 2
versi, yaitu python 2 dan python 3. Versi yang terbaru adalah versi
yang ketiga.
Python dapat digunakan sebagai berikut :
- Pengembangan aplikasi web dan seluler back end (atau sisi server)
- Pengembangan aplikasi atau perangkat lunak untuk dekstop
- Memproses data besar dan melakukan perhitungan matematis
- Menulis skrip sistem (membuat instruksi yang memberitahu sistem komputer untuk “melakukan” sesuatu)
Menentukan Nilai k
Menentukan nilai k atau jumlah tetangga merupakan langkah awal untuk membangun model pembelajaran berdasarkan algoritma K-Nearest Neighbor. Nilai k merupakan jumlah data yang diperhitungkan dalam menentukkan klasifikasi saat ada input data yang baru. Misal jika kita ingin mengelompokkan sebuah nilai yang dapat digambarkan pada bidang kartesius, lalu kita tentukkan nilai k sebanyak tiga (tiga tetangga terdekat), maka nilai tersebut akan menetapkan tiga tetangga terdekatnya.

Data/objek baru tersebut akan diklasifikasikan sebagai Kelompok B karena data tersebut memiliki tetangga Kelompok B yang lebih banyak (dua tetangga), sedangkan data tersebut hanya memiliki satu tetangga Kelompok A. Jika kita ubah nilai k-nya, maka penentuan jumlah tetangganya pun akan sedikit berubah. Semisal kita ubah nilai k menjadi 5.

Data tersebut akan diklasifikasikan sebagai Kelompok A karena memiliki tetangga anggota Kelompok A sebanyak 3, dibandingkan dengan kedekatannya dengan anggota Kelompok B yang hanya 2. Penentuan k atau jumlah tetangga terdekat ini merupakan konsep yang penting pada algoritma KNN.
Distance Metrics
Sebelumnya sedikit disinggung mengenai matriks penghitungan jarak atau distance metrics yang umum digunakan pada algoritma KNN untuk mengukur kedekatan objek dengan data terdekat yaitu Euclidean distance, Minkowski distance, dan Manhattan distance. Untuk membuat sebuah model pembelajaran mesin dengan performa yang baik tentu tidak cukup menggunakan parameter atau metode default saja. Dengan ketiga metode matriks perhitungan jarak yang berbeda-beda, memungkinkan kita mendapatkan model pembelajaran performa terbaik.
Euclidean Distance
Euclidean distance adalah metode penghitungan jarak garis lurus terhadap dua objek yang berbeda. Metode ini dapat diterapkan ke dalam ruang 1, 2, dan 3 dimensi[6]. Penghitungan jarak pada ruang 1-dimensional dapat digambarkan dengan formula sebagai berikut.
Dalam implementasinya pada model pembelajaran mesin, rumus penghitungannya dapat berubah tergantung banyaknya independent variabel pada dataset yang digunakan sebagai data latih. Jika dataset memiliki dua atau lebih independent variabel begitu juga dimensi yang dihitungnya bertambah, maka formulanya menjadi seperti berikut.
Manhattan Distance
Manhattan distance digunakan untuk mengambil kasus yang cocok dari basis kasus dengan menghitung jumlah bobot absolute dari perbedaan antara kasus yang sekarang dan kasus yang lain[7]. Untuk menghitung bobot digunakan persamaan berikut:
Dimana diketahui dij adalah jarak antara kasus antara i th dan jth dengan semua parameternya. W merepresentasikan jumlah dari bobot. X adalah kasus yang baru dikurangi dengan C yaitu history (kasus yang ada dalam Casse Base).
Minkowski Distance
Minkowski distance merupakan sebuah metrik dalam ruang vektor di mana suatu norma didefinisikan (normed vector space) sekaligus dianggap sebagai generalisasi dari Euclidean distance dan Manhattan distance. Dalam pengukuran jarak objek menggunakan Minkowski distance biasanya digunakan nilai p adalah 1 atau 2[8]. Berikut rumus yang digunakan menghitung jarak dalam metode ini.
Dimana.
d = jarak antara x dan y
x = data pusat klaster
y = data pada atribut
i = setiap data
n = jumlah data,
xi = data pada pusat klaster ke i
yi = data pada setiap data ke i
p = power
Variabel Pengujian
Dalam data set untuk menentukan apakah seseorang menderita diabetes atau tidak terdapat 9 variabel yang terdiri dari 8 variabel independen(x) dan 1 variabel dependen(y). Adapun variabel independen (x) sebagai berikut:
a. Pregnancies: persentasi berapa kali seorang wanita pernah hamil selama hidupnya
b. Insulin: tingkat insulin dalam 2 jam insulin serum dengan satuan mu U/ml
c. Glucose: persentasi gula darah pada 2 jam dalam tes toleransi glukosa
d. BMI: indeks massa tubuh (berat dalam kg/tinggi dalam meter)
e. Blood Presure: tekanan darah dalam satuan mm/hg
f. Diabetes Pidegree Function: indikator riwayat diabetes dalam keluarga atau keturunan
g. Skin Thickness: nilai yang digunakan untuk mengukur lemak tubuh yang diukur pada lengan
kanan setengah antara proses olecranon dari siku dan proses akromial
h. Age: umur dari seorang sample
sedangkan variabel dependen(y) merupakan output dari hasil prediksi dengan class variable 0 atau 1, 0 untuk tidak mengidap diabetes dan 1 untuk hasil positif mengidap diabetes
- Metode Penelitian
Metode penelitian yang digunakan adalah R&D atau Research and Development, yaitu metode yang bertujuan untuk dapat mengembangkan produk lalu menguji dan mengembangkannya sampai produk tersebut dapat berjalan sesuai yang diharapkan [9].
- Hasil
A. Membaca data set dan mengubah ke data frame
B. Pembacaan informasi pada data frame
C. Nilai Stastistik data
D. Import nilai train_test_split
E. Pengklasifikasian nilai knn dengan nilai k neighbors
F. Import Cofussion Matrix


G. Program:
# Import Library yang perlu digunakan
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Membaca dataset dan merubah ke dataframe
data_diabetes = pd.read_csv('diabetes.csv')
data_diabetes
# Melihat informasi dataframe
data_diabetes.info()
# Melihat statistik data
data_diabetes.describe()
# Melihat data yang bernilai NULL
data_diabetes.isnull().sum()
# EDA
data_diabetes.corr()
# Visualisasi Korelasi
plt.figure(figsize=(12,8))
sns.heatmap(data_diabetes.corr(), annot =True)
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X = pd.DataFrame(sc_X.fit_transform(data_diabetes.drop(["Outcome"],axis = 1),),
columns=['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin',
'BMI', 'DiabetesPedigreeFunction', 'Age'])
X
y = data_diabetes.Outcome
y
#importing train_test_split
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.8,test_size = 0.2 , random_state=42, stratify=y)
from sklearn.neighbors import KNeighborsClassifier
test_scores = []
train_scores = []
for i in range(1,15):
knn = KNeighborsClassifier(i)
knn.fit(X_train,y_train)
train_scores.append(knn.score(X_train,y_train))
test_scores.append(knn.score(X_test,y_test))
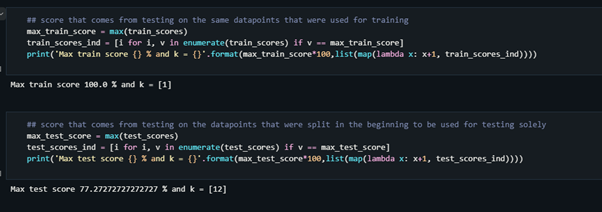
## score that comes from testing on the same datapoints that were used for training
max_train_score = max(train_scores)
train_scores_ind = [i for i, v in enumerate(train_scores) if v == max_train_score]
print('Max train score {} % and k = {}'.format(max_train_score*100,list(map(lambda x: x+1, train_scores_ind))))
## score that comes from testing on the datapoints that were split in the beginning to be used for testing solely
max_test_score = max(test_scores)
test_scores_ind = [i for i, v in enumerate(test_scores) if v == max_test_score]
print('Max test score {} % and k = {}'.format(max_test_score*100,list(map(lambda x: x+1, test_scores_ind))))
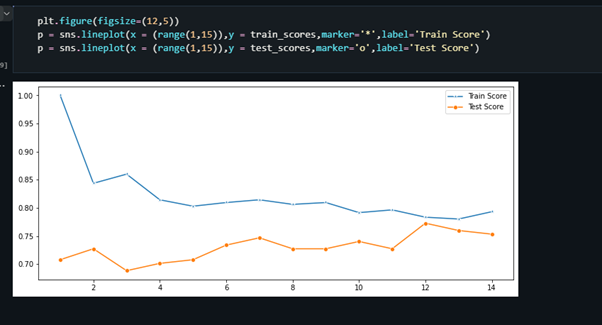
plt.figure(figsize=(12,5))
p = sns.lineplot(x = (range(1,15)),y = train_scores,marker='*',label='Train Score')
p = sns.lineplot(x = (range(1,15)),y = test_scores,marker='o',label='Test Score')
#Setup a knn classifier with k neighbors
knn = KNeighborsClassifier(12)
knn.fit(X_train,y_train)
knn.score(X_test,y_test)
# Performance Analysis
#import confusion_matrix
from sklearn.metrics import confusion_matrix
#let us get the predictions using the classifier we had fit above
y_pred = knn.predict(X_test)
confusion_matrix(y_test,y_pred)
pd.crosstab(y_test, y_pred, rownames=['True'], colnames=['Predicted'], margins=True)
y_pred = knn.predict(X_test)
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
p = sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
#import classification_report
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
#import GridSearchCV
from sklearn.model_selection import GridSearchCV
#In case of classifier like knn the parameter to be tuned is n_neighbors
param_grid = {'n_neighbors':np.arange(1,50)}
knn = KNeighborsClassifier()
knn_cv= GridSearchCV(knn,param_grid,cv=5)
knn_cv.fit(X,y)
print("Best Score:" + str(knn_cv.best_score_))
print("Best Parameters: " + str(knn_cv.best_params_))
H. Hasil :

- Kesimpulan
Diabetes Prediction secara keseluruhan telah berhasil dibangun menggunakan dataset Pima Indian Diabetes Database. Aplikasi ini telah dapat berfungsi sebagaimana mestinya yaitu user diminta untuk menginputkan data pregnancies(angke kehamilan seseorang selama dia hidup), kadar insulin, kadar glukosa, BMI, Tekanan darah, riwayat diabetes dalam keluarga, ketebalan kulit, dan umur dalam bentuk slider. Data input diproses dengan algoritma KNN untuk menentukan hasil Outcome berupa hasil positif diabetes atau negatif berdasarkan kedekatan data baru yang di input dengan data lain yang telah dilatih.
- Saran














Comments
Post a Comment